Bayesian Network¶
[1]:
from IPython.display import Image
Bayesian Models¶
What are Bayesian Models
Independencies in Bayesian Networks
How is Bayesian Model encoding the Joint Distribution
How we do inference from Bayesian models
Types of methods for inference
1. What are Bayesian Models¶
A Bayesian network, Bayes network, belief network, Bayes(ian) model or probabilistic directed acyclic graphical model is a probabilistic graphical model (a type of statistical model) that represents a set of random variables and their conditional dependencies via a directed acyclic graph (DAG). Bayesian networks are mostly used when we want to represent causal relationship between the random variables. Bayesian Networks are parameterized using Conditional Probability Distributions (CPD). Each
node in the network is parameterized using 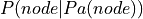 where
where 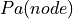 represents the parents of node in the network.
represents the parents of node in the network.
We can take the example of the student model:
[2]:
Image('../images/2/student_full_param.png')
[2]:

In pgmpy we define the network structure and the CPDs separately and then associate them with the structure. Here’s an example for defining the above model:
[36]:
from pgmpy.models import BayesianModel
from pgmpy.factors.discrete import TabularCPD
# Defining the model structure. We can define the network by just passing a list of edges.
model = BayesianModel([('D', 'G'), ('I', 'G'), ('G', 'L'), ('I', 'S')])
# Defining individual CPDs.
cpd_d = TabularCPD(variable='D', variable_card=2, values=[[0.6], [0.4]])
cpd_i = TabularCPD(variable='I', variable_card=2, values=[[0.7], [0.3]])
# The representation of CPD in pgmpy is a bit different than the CPD shown in the above picture. In pgmpy the colums
# are the evidences and rows are the states of the variable. So the grade CPD is represented like this:
#
# +---------+---------+---------+---------+---------+
# | diff | intel_0 | intel_0 | intel_1 | intel_1 |
# +---------+---------+---------+---------+---------+
# | intel | diff_0 | diff_1 | diff_0 | diff_1 |
# +---------+---------+---------+---------+---------+
# | grade_0 | 0.3 | 0.05 | 0.9 | 0.5 |
# +---------+---------+---------+---------+---------+
# | grade_1 | 0.4 | 0.25 | 0.08 | 0.3 |
# +---------+---------+---------+---------+---------+
# | grade_2 | 0.3 | 0.7 | 0.02 | 0.2 |
# +---------+---------+---------+---------+---------+
cpd_g = TabularCPD(variable='G', variable_card=3,
values=[[0.3, 0.05, 0.9, 0.5],
[0.4, 0.25, 0.08, 0.3],
[0.3, 0.7, 0.02, 0.2]],
evidence=['I', 'D'],
evidence_card=[2, 2])
cpd_l = TabularCPD(variable='L', variable_card=2,
values=[[0.1, 0.4, 0.99],
[0.9, 0.6, 0.01]],
evidence=['G'],
evidence_card=[3])
cpd_s = TabularCPD(variable='S', variable_card=2,
values=[[0.95, 0.2],
[0.05, 0.8]],
evidence=['I'],
evidence_card=[2])
# Associating the CPDs with the network
model.add_cpds(cpd_d, cpd_i, cpd_g, cpd_l, cpd_s)
# check_model checks for the network structure and CPDs and verifies that the CPDs are correctly
# defined and sum to 1.
model.check_model()
[36]:
True
[37]:
# CPDs can also be defined using the state names of the variables. If the state names are not provided
# like in the previous example, pgmpy will automatically assign names as: 0, 1, 2, ....
cpd_d_sn = TabularCPD(variable='D', variable_card=2, values=[[0.6], [0.4]], state_names={'D': ['Easy', 'Hard']})
cpd_i_sn = TabularCPD(variable='I', variable_card=2, values=[[0.7], [0.3]], state_names={'I': ['Dumb', 'Intelligent']})
cpd_g_sn = TabularCPD(variable='G', variable_card=3,
values=[[0.3, 0.05, 0.9, 0.5],
[0.4, 0.25, 0.08, 0.3],
[0.3, 0.7, 0.02, 0.2]],
evidence=['I', 'D'],
evidence_card=[2, 2],
state_names={'G': ['A', 'B', 'C'],
'I': ['Dumb', 'Intelligent'],
'D': ['Easy', 'Hard']})
cpd_l_sn = TabularCPD(variable='L', variable_card=2,
values=[[0.1, 0.4, 0.99],
[0.9, 0.6, 0.01]],
evidence=['G'],
evidence_card=[3],
state_names={'L': ['Bad', 'Good'],
'G': ['A', 'B', 'C']})
cpd_s_sn = TabularCPD(variable='S', variable_card=2,
values=[[0.95, 0.2],
[0.05, 0.8]],
evidence=['I'],
evidence_card=[2],
state_names={'S': ['Bad', 'Good'],
'I': ['Dumb', 'Intelligent']})
# These defined CPDs can be added to the model. Since, the model already has CPDs associated to variables, it will
# show warning that pmgpy is now replacing those CPDs with the new ones.
model.add_cpds(cpd_d_sn, cpd_i_sn, cpd_g_sn, cpd_l_sn, cpd_s_sn)
model.check_model()
WARNING:root:Replacing existing CPD for D
WARNING:root:Replacing existing CPD for I
WARNING:root:Replacing existing CPD for G
WARNING:root:Replacing existing CPD for L
WARNING:root:Replacing existing CPD for S
[37]:
True
[38]:
# We can now call some methods on the BayesianModel object.
model.get_cpds()
[38]:
[<TabularCPD representing P(D:2) at 0x7f1585d3e278>,
<TabularCPD representing P(I:2) at 0x7f1585d3e320>,
<TabularCPD representing P(G:3 | I:2, D:2) at 0x7f1585d3e390>,
<TabularCPD representing P(L:2 | G:3) at 0x7f1585d3e2b0>,
<TabularCPD representing P(S:2 | I:2) at 0x7f1585d3e358>]
[39]:
# Printing a CPD which doesn't have state names defined.
print(cpd_g)
+------+------+------+------+------+
| I | I(0) | I(0) | I(1) | I(1) |
+------+------+------+------+------+
| D | D(0) | D(1) | D(0) | D(1) |
+------+------+------+------+------+
| G(0) | 0.3 | 0.05 | 0.9 | 0.5 |
+------+------+------+------+------+
| G(1) | 0.4 | 0.25 | 0.08 | 0.3 |
+------+------+------+------+------+
| G(2) | 0.3 | 0.7 | 0.02 | 0.2 |
+------+------+------+------+------+
[40]:
# Printing a CPD with it's state names defined.
print(model.get_cpds('G'))
+------+---------+---------+----------------+----------------+
| I | I(Dumb) | I(Dumb) | I(Intelligent) | I(Intelligent) |
+------+---------+---------+----------------+----------------+
| D | D(Easy) | D(Hard) | D(Easy) | D(Hard) |
+------+---------+---------+----------------+----------------+
| G(A) | 0.3 | 0.05 | 0.9 | 0.5 |
+------+---------+---------+----------------+----------------+
| G(B) | 0.4 | 0.25 | 0.08 | 0.3 |
+------+---------+---------+----------------+----------------+
| G(C) | 0.3 | 0.7 | 0.02 | 0.2 |
+------+---------+---------+----------------+----------------+
[41]:
model.get_cardinality('G')
[41]:
3
2. Independencies in Bayesian Networks¶
Independencies implied by the network structure of a Bayesian Network can be categorized in 2 types:
Local Independencies: Any variable in the network is independent of its non-descendents given its parents. Mathematically it can be written as:
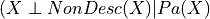
where
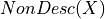 is the set of variables which are not descendents of
is the set of variables which are not descendents of 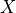 and
and 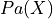 is the set of variables which are parents of .
is the set of variables which are parents of .Global Independencies: For discussing global independencies in Bayesian Networks we need to look at the various network structures possible. Starting with the case of 2 nodes, there are only 2 possible ways for it to be connected:
[42]:
Image('../images/2/two_nodes.png')
[42]:

In the above two cases it is fairly obvious that change in any of the node will affect the other. For the first case we can take the example of 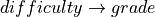 . If we increase the difficulty of the course the probability of getting a higher grade decreases. For the second case we can take the example of
. If we increase the difficulty of the course the probability of getting a higher grade decreases. For the second case we can take the example of 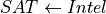 . Now if we increase the probability of getting a good score in SAT that would imply that the student is intelligent, hence increasing the
probability of
. Now if we increase the probability of getting a good score in SAT that would imply that the student is intelligent, hence increasing the
probability of 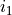 . Therefore in both the cases shown above any change in the variables leads to change in the other variable.
. Therefore in both the cases shown above any change in the variables leads to change in the other variable.
Now, there are four possible ways of connection between 3 nodes:
[43]:
Image('../images/2/three_nodes.png')
[43]:

Now in the above cases we will see the flow of influence from 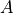 to
to 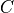 under various cases.
under various cases.
Causal: In the general case when we make any changes in the variable
, it will have effect of variable 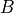 (as we discussed above) and this change in will change the values in . One other possible case can be when is observed i.e. we know the value of . So, in this case any change in won’t affect since we already know the value. And hence there won’t be any change in as it depends only on .
Mathematically we can say that:
(as we discussed above) and this change in will change the values in . One other possible case can be when is observed i.e. we know the value of . So, in this case any change in won’t affect since we already know the value. And hence there won’t be any change in as it depends only on .
Mathematically we can say that: 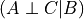 .
.Evidential: Similarly in this case also observing
renders independent of . Otherwise when is not observed the influence flows from to . Hence .Common Evidence: This case is a bit different from the others. When
is not observed any change in reflects some change in but not in . Let’s take the example of 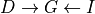 . In this case if we increase the difficulty of the course the probability of getting a higher grade reduces but this has no effect on the intelligence of the student. But when is observed let’s say that the student got a good grade. Now if we
increase the difficulty of the course this will increase the probability of the student to be intelligent since we already know that he got a good grade. Hence in this case
. In this case if we increase the difficulty of the course the probability of getting a higher grade reduces but this has no effect on the intelligence of the student. But when is observed let’s say that the student got a good grade. Now if we
increase the difficulty of the course this will increase the probability of the student to be intelligent since we already know that he got a good grade. Hence in this case 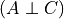 and
and 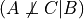 . This structure is also commonly known as V structure.
. This structure is also commonly known as V structure.Common Cause: The influence flows from
to when is not observed. But when is observed and change in doesn’t affect since it’s only dependent on . Hence here also 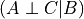 .
.
Let’s not see a few examples for finding the independencies in a newtork using pgmpy:
[44]:
# Getting the local independencies of a variable.
model.local_independencies('G')
[44]:
(G _|_ S | I, D)
[45]:
# Getting all the local independencies in the network.
model.local_independencies(['D', 'I', 'S', 'G', 'L'])
[45]:
(D _|_ I, S)
(I _|_ D)
(S _|_ G, L, D | I)
(G _|_ S | I, D)
(L _|_ I, D, S | G)
[48]:
# Active trail: For any two variables A and B in a network if any change in A influences the values of B then we say
# that there is an active trail between A and B.
# In pgmpy active_trail_nodes gives a set of nodes which are affected (i.e. correlated) by any
# change in the node passed in the argument.
model.active_trail_nodes('D')
[48]:
{'D': {'D', 'G', 'L'}}
[49]:
model.active_trail_nodes('D', observed='G')
[49]:
{'D': {'D', 'I', 'S'}}
3. How is this Bayesian Network representing the Joint Distribution over the variables ?¶
Till now we just have been considering that the Bayesian Network can represent the Joint Distribution without any proof. Now let’s see how to compute the Joint Distribution from the Bayesian Network.
From the chain rule of probabiliy we know that:
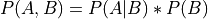
Now in this case:
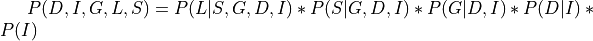
Applying the local independence conditions in the above equation we will get:
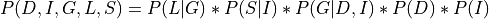
From the above equation we can clearly see that the Joint Distribution over all the variables is just the product of all the CPDs in the network. Hence encoding the independencies in the Joint Distribution in a graph structure helped us in reducing the number of parameters that we need to store.
4. Inference in Bayesian Models¶
Till now we discussed just about representing Bayesian Networks. Now let’s see how we can do inference in a Bayesian Model and use it to predict values over new data points for machine learning tasks. In this section we will consider that we already have our model. We will talk about constructing the models from data in later parts of this tutorial.
In inference we try to answer probability queries over the network given some other variables. So, we might want to know the probable grade of an intelligent student in a difficult class given that he scored good in SAT. So for computing these values from a Joint Distribution we will have to reduce over the given variables that is 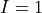 ,
, 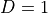 ,
, 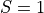 and then marginalize over the other variables that is
and then marginalize over the other variables that is 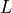 to get
to get 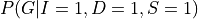 . But carrying on
marginalize and reduce operation on the complete Joint Distribution is computationaly expensive since we need to iterate over the whole table for each operation and the table is exponential is size to the number of variables. But in Graphical Models we exploit the independencies to break these operations in smaller parts making it much faster.
. But carrying on
marginalize and reduce operation on the complete Joint Distribution is computationaly expensive since we need to iterate over the whole table for each operation and the table is exponential is size to the number of variables. But in Graphical Models we exploit the independencies to break these operations in smaller parts making it much faster.
One of the very basic methods of inference in Graphical Models is Variable Elimination.
Variable Elimination¶
We know that:
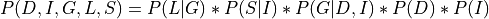
Now let’s say we just want to compute the probability of G. For that we will need to marginalize over all the other variables.
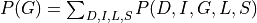
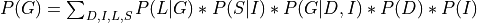
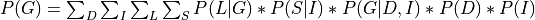
Now since not all the conditional distributions depend on all the variables we can push the summations inside:
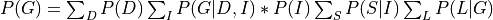
So, by pushing the summations inside we have saved a lot of computation because we have to now iterate over much smaller tables.
Let’s take an example for inference using Variable Elimination in pgmpy:
[52]:
from pgmpy.inference import VariableElimination
infer = VariableElimination(model)
g_dist = infer.query(['G'])
print(g_dist)
Finding Elimination Order: : 100%|██████████| 4/4 [00:00<00:00, 1210.13it/s]
Eliminating: I: 100%|██████████| 4/4 [00:00<00:00, 240.56it/s]
+------+----------+
| G | phi(G) |
+======+==========+
| G(A) | 0.3620 |
+------+----------+
| G(B) | 0.2884 |
+------+----------+
| G(C) | 0.3496 |
+------+----------+
There can be cases in which we want to compute the conditional distribution let’s say 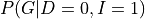 . In such cases we need to modify our equations a bit:
. In such cases we need to modify our equations a bit:
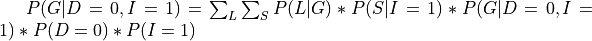
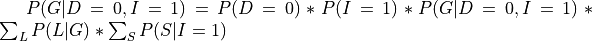
In pgmpy we will just need to pass an extra argument in the case of conditional distributions:
[58]:
print(infer.query(['G'], evidence={'D': 'Easy', 'I': 'Intelligent'}))
Finding Elimination Order: : 100%|██████████| 2/2 [00:00<00:00, 552.57it/s]
Eliminating: S: 100%|██████████| 2/2 [00:00<00:00, 326.68it/s]
+------+----------+
| G | phi(G) |
+======+==========+
| G(A) | 0.9000 |
+------+----------+
| G(B) | 0.0800 |
+------+----------+
| G(C) | 0.0200 |
+------+----------+
Predicting values from new data points¶
Predicting values from new data points is quite similar to computing the conditional probabilities. We need to query for the variable that we need to predict given all the other features. The only difference is that rather than getting the probabilitiy distribution we are interested in getting the most probable state of the variable.
In pgmpy this is known as MAP query. Here’s an example:
[59]:
infer.map_query(['G'])
Finding Elimination Order: : 100%|██████████| 4/4 [00:00<00:00, 1073.12it/s]
Eliminating: I: 100%|██████████| 4/4 [00:00<00:00, 273.20it/s]
[59]:
{'G': 'A'}
[60]:
infer.map_query(['G'], evidence={'D': 'Easy', 'I': 'Intelligent'})
Finding Elimination Order: : 100%|██████████| 2/2 [00:00<00:00, 417.30it/s]
Eliminating: S: 100%|██████████| 2/2 [00:00<00:00, 219.08it/s]
[60]:
{'G': 'A'}
[61]:
infer.map_query(['G'], evidence={'D': 'Easy', 'I': 'Intelligent', 'L': 'Good', 'S': 'Good'})
Finding Elimination Order: : : 0it [00:00, ?it/s]
0it [00:00, ?it/s]
[61]:
{'G': 'A'}
5. Other methods for Inference¶
Even though exact inference algorithms like Variable Elimination optimize the inference task, it is still computationally quite expensive in the case of large models. For such cases we can use approximate algorithms like Message Passing Algorithms, Sampling Algorithms etc. We will talk about a few other exact and approximate algorithms in later parts of the tutorial.